超解像(Super Resolution)とは? 仕組みと歴史、さくらでの実現方法について解説

今日のディスプレイの進化には目覚ましいものがあります。家電量販店に足を運べば、高精細で鮮明な映像がテレビやスマートフォンに表示されており、つい足を止めてしまいます。そのようななかで、古い画像やズーム撮影された写真を並べてみると、少し見劣りしてしまうことも。今回はそうした画像の品質改善を試みる技術の1つである、超解像について解説します。
注釈:画像と同様に動画についても超解像技術が普及していますが、ここでは単一画像の超解像についてのみ扱います。
超解像とは
超解像(Super-resolution)とは、低解像度の画像データを、高解像度に変換する技術です。最新型のスマートフォンでズーム撮影をすると、最初はぼやけていても、数秒で高精細な画像に変わったことはないでしょうか。あれは「ピントが合っている」だけではなく、裏でAIによる超解像処理が走っています。同様の技術を用いることで、制作当時の環境やデータ容量の制約のために低解像度で持っていた画像データでも、現代の表示画面に応えうる、高解像度のものに変換することが可能です。
どのような処理をしている?
本来ないはずの高精細画像が出せる、と聞くと、魔法のような技術と思われるかもしれません。実際にどのような処理をしているか、大まかに解説します。
画像データの仕組み
本題に入る前に、画像データの仕組みについておさらいしましょう。
画像データは、おもに「画素」と「色情報」から成り立っています(式で表現するベクター画像についてはここでは扱いません)。
画素(ピクセル)とは、画像の面積を構成する最小の点です。画像データは、極小の四角形を大量に並べることで表現されています。タイル画を限界まで細かくしたようなイメージです。滑らかに表示されている画像でも、大きく拡大していくと、ギザギザして見えたことはありませんか? あれは、遠くから見ていてはわからないほど微細だった画素の辺が、拡大したことによって見えてしまった状態です。500万画素、と言われたら、それは、その画像が500万個の四角形から構成されていることを意味します。
色情報とは、その各画素に、どのような色を持たせるかを意味します。どれくらい細かく色を表現できるかによって、色の繊細さが変わります。白黒のみの2段階、白黒に濃淡も加えた256段階のグレースケール、1677万色に対応したフルカラーまで、さまざまな仕様があります。
本来の絵を、「画素」に分割し、各画素に「色情報」を持たせたもの。それが画像データの正体なのです。
超解像で実現していること
超解像では、おもに2つの処理をおこなっています。
1つ目は、単純に「画素」を増やす作業です。もともとn個の画素で表現されていた画像を、4n個や16n個で表現できるようにします。しかし、単純に画素を増やしただけでは、ただ画像を拡大したときのように、重いギザギザの画像ができるだけです。
そこで、2つ目の作業「推定・補完」をセットでおこないます。増えた画素数分、本来そこにあったはずの色情報を推定し、復元するわけです。そうすることで、元画像より滑らかな画像を生成します。
超解像の仕組みと歴史
推定ってどうやってやるの? と思われた方も多いでしょう。その仕組みと歴史について、簡単にご説明します。単一の画像を超解像する方式と、複数画像を紐づけて超解像をおこなう方式がありますが、今回はImageFlux利用者の使用形態に近いと思われる、前者に絞って解説します。
単純計算の時代
実はAIが登場する前も、超解像技術は存在していました。
この時代は、おもに2種類の方法で、超解像を実現していました。
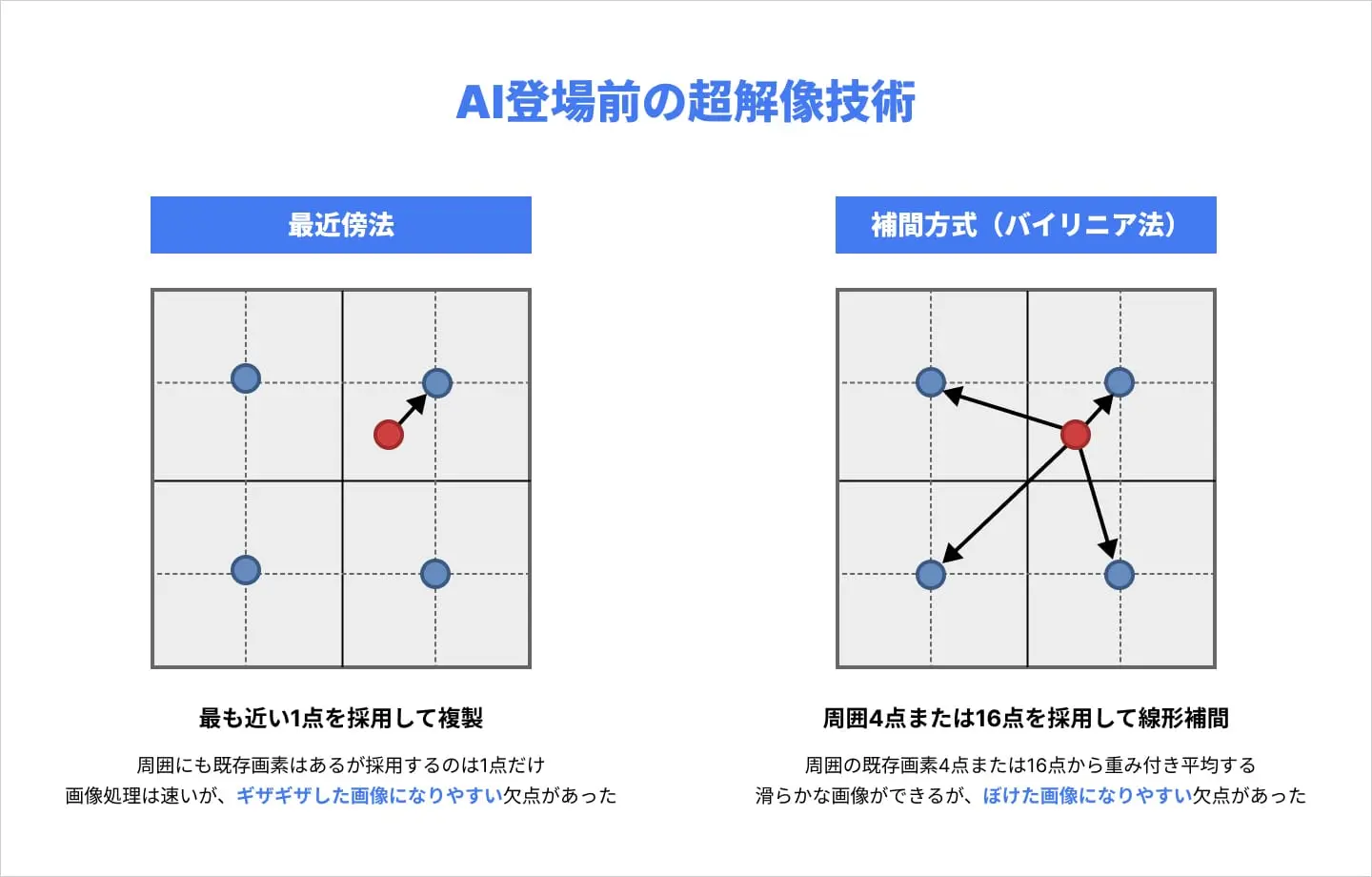
最近傍法
もっとも単純な方式で、新しく作成した画素に、隣接する画素の情報をそのまま複製する方式です。計算が単純であるため処理は速いですが、そのまま拡大しているのとほぼ同義であるため、ギザギザした画像になりやすいという欠点がありました。
補間方式
新画素に近い4個(または16個)の画素の加重平均を求め、その値で新画素を埋めるという方式です。単純に隣接画素を複製するのではなく、「この画素とこの画素の間なのだから、中間くらいの色なのではないか」と計算で推定するわけです。計算量は増えますが、最近傍法より滑らかな画像が生成できました。しかし、色の移り変わりが激しい画像データは、超解像後にぼやけたものになりやすいという欠点がありました。
機械学習の時代
AI、機械学習の時代になると、超解像の品質は大きく押し上げられます。
AIによる実装においては、まず高品質な画像と、それをあえて劣化させた画像のペアを用意します。機械学習に用いますから、大量のペア画像データが必要です。このペアを元に、「こういった画像はこういうふうに劣化するから、逆パターンで計算すれば元通りになる」というパターンを学習させるわけです。
用いられる技術はおもに2つあります。
CNN
畳み込みニューラルネットワークと呼ばれ、画像の上をカーネル(小さなフィルター)がスライドしながら情報を読み取り、読み取った情報を圧縮・要約しながら、画像の特徴を抽出していく仕組みです。
超解像においては、これを「本来はこういう画像があったんだろう」という推定に用います。
GAN
敵対的生成ネットワーク、と呼ばれます。物々しい名前ですが、やっていることは単純です。生成器(Generator)と識別器(Discriminator)という2つの機構からなり、生成器側は本物らしい画像を生成しようと試み、識別器側は本物と偽物を識別しようと試みます。この2つが高めあいながら学習していくことで、画像精度を向上させていきます。
さくらインターネットのサービスで実現してみる
AIを用いた超解像は、高品質な出力が得られる一方で、処理が重くなりがちです。画像CDN側でこれを実現すると、レスポンスが遅くなってしまう場合があり、2026年2月時点でImageFluxはこの処理に対応していません。
しかし、あらかじめ超解像で高解像度のデータを用意しておき、配信時には各端末に最適化した画質で配信することなら可能です。配信を含めて超解像を考えるのであれば、おそらくこれが最適解になるでしょう。
今回は、高火力DOKとオブジェクトストレージを併用する形で実現してみました。処理の概要は以下のとおりです。ソースコードはこちらで公開しています。
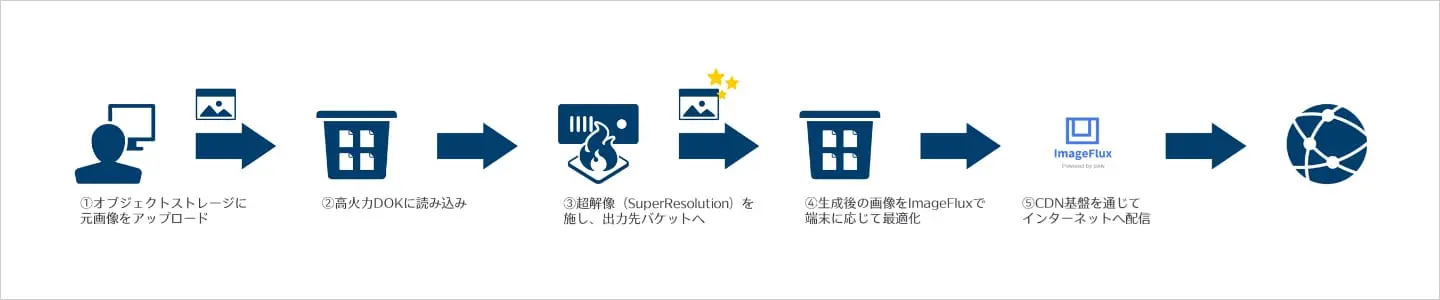
- オブジェクトストレージに超解像する画像を格納する。
- 高火力DOKで超解像処理を実行する。
- 処理結果をオブジェクトストレージに格納する。
- ImageFluxで配信する。
まず、オブジェクトストレージに超解像する元画像をアップロードします。
次に、高火力DOK上で超解像処理を実行します。今回はReal-ESRGANというオープンソースの超解像ツールをDockerイメージに格納しました。ロジックは単純で、入出力バケットとファイルパスを受け取り、成果物をオブジェクトストレージに再格納します。
縦横4倍に超解像してみます。
高火力DOK・タスク完了画面
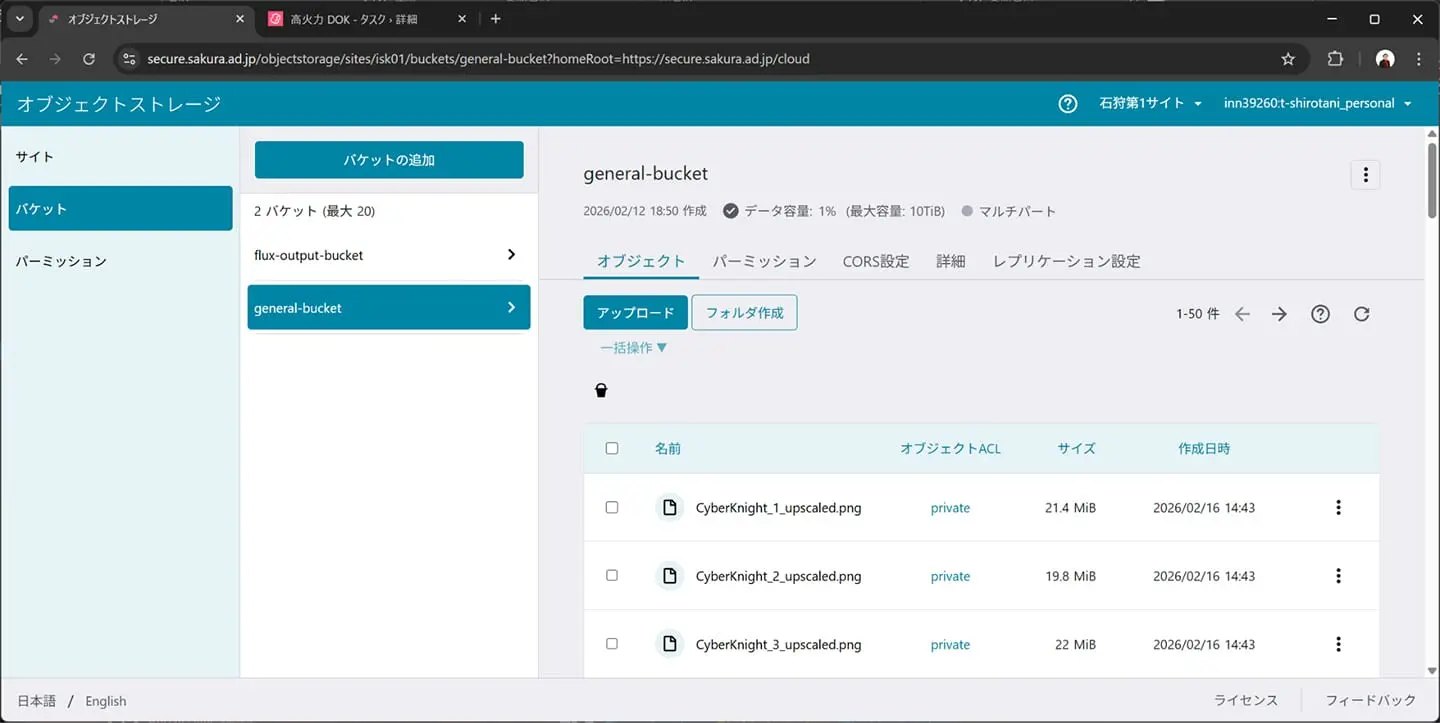
オブジェクトストレージの出力先バケット。
超解像後の画像が格納されています。1.5MiBが21.4MiBになっているのは、縦横4倍で、面積としては計16倍になるためです。高画質ではありますが、このまま配信するにはデータ容量が非常に大きいため、あくまでこの画像はmasterとして保管し、配信時にはImageFluxで最適化をおこないます。
出力先バケットをオリジンに登録し、
プレビュー画面でプレビューします。大き過ぎて左上しか表示できていませんね。
今回は配信用に640pxにリサイズし、フォーマットもWebPにしてみました。
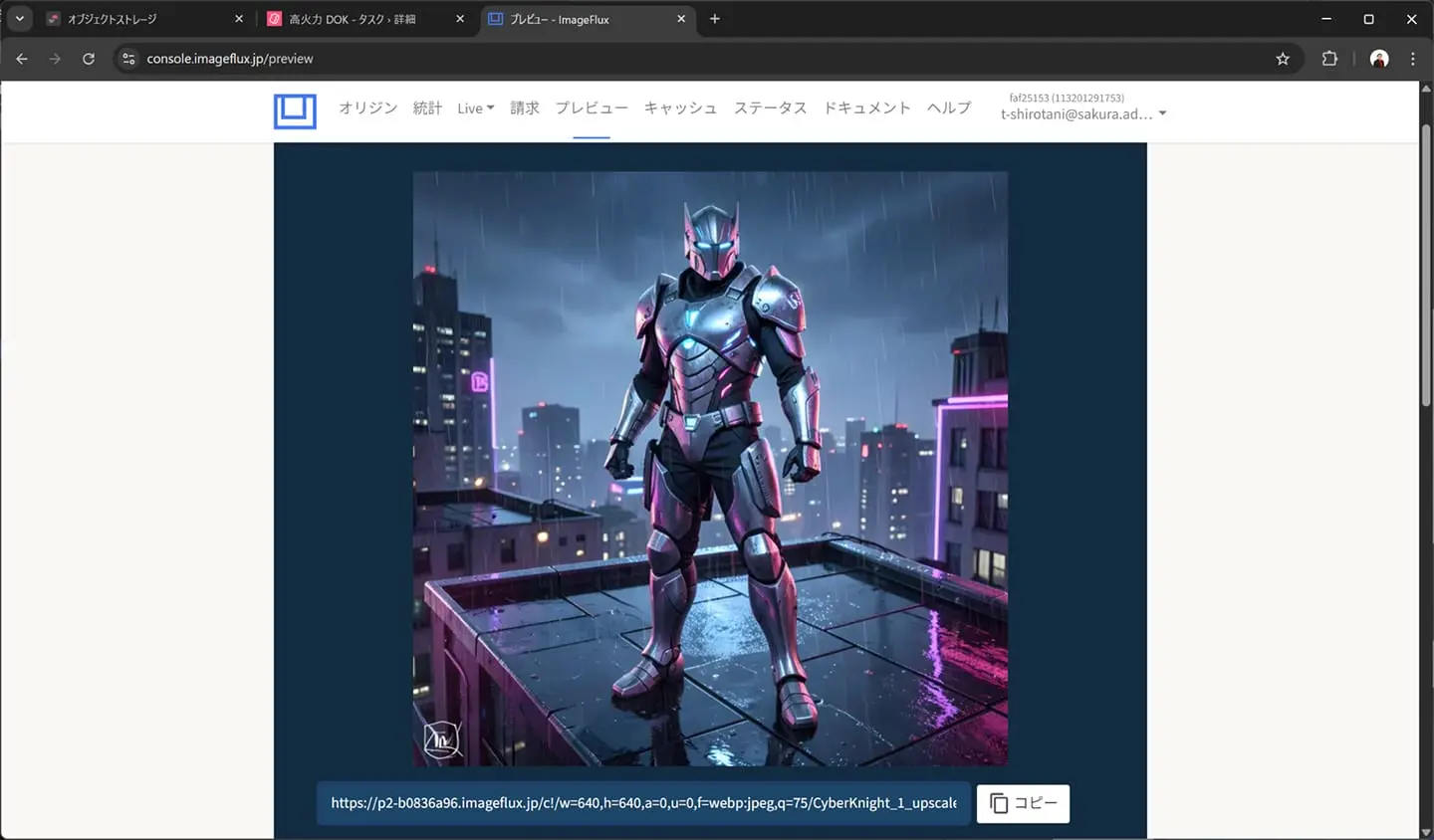
サイズは50KBまで削減できています。これで超解像で高解像度のデータを用意して、配信時には最適化した画質で配信する設定ができました。

まとめ
今回は、超解像の概要とその実現方法について解説してきました。
ここまで読まれた方はお察しのとおり、超解像とは、元の画像を完全に再現する技術ではありません。あくまでそれを推定し、描画する技術です。そのため、想定外の出力になる可能性もゼロではありません。商業ユースの配信にあたって品質保証をしたい場合は、超解像後の画像をあらかじめ確認してから、最適化して配信することをおすすめします。
機械学習とともに進歩した超解像技術、ぜひ上手に利活用してみてください!
ImageFluxチーム
さくらインターネットとピクシブで共同開発・提供している、クラウド画像変換サービス・ライブ配信エンジンサービス「ImageFlux」のチームです。
